|
|
||
|---|---|---|
| .. | ||
| doe-cv-build | ||
| em-cv-build | ||
| pw-cv-build | ||
| README.md | ||
| build-termlist.ipynb | ||
| build-termlist.py | ||
| build.py | ||
| generate_term_versions.py | ||
| qrg-list.csv | ||
| requirements.txt | ||
| termlist-footer.md | ||
| termlist-header.md | ||
| terms.tmpl | ||
| workflow_diagram.png | ||
{kind=link}
README.md
Workflow for generating a new version of Darwin Core
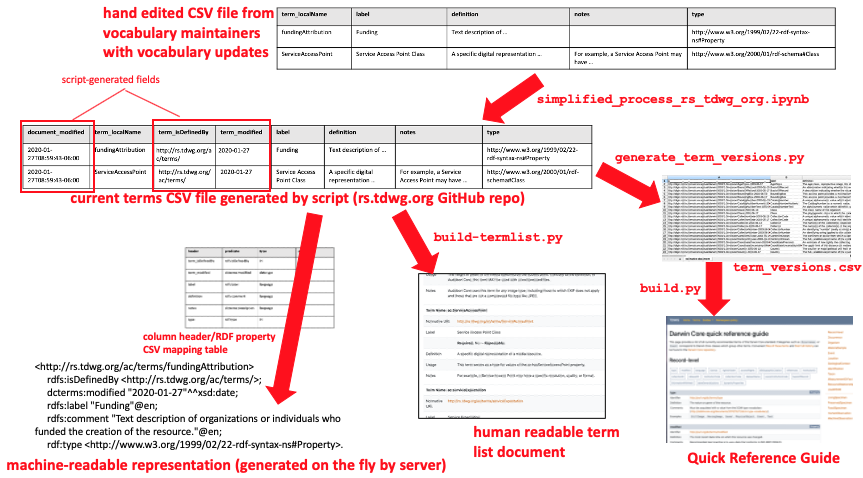
- Download the CSV file for the terms in the namespace to be modified. The
dwc:namespace terms are here,dwciri:terms are here,dc:terms are here, and thedcterms:terms are here. - Note: It is highly recommended that you do not hand-edit the raw CSVs with a text editor. Use Libre Office or Open Office (NOT Excel). They will reliably open, close, and edit the file while preserving and escaping commas, quotes, etc. and also not mess up the UTF-8 encoding if you set them up properly. Delete the columns that do not serve as input to the system. They are:
document_modified,term_isDefinedBy,term_created,term_modified,term_deprecated,replaces_term,replaces1_term, andreplaces2_term. That should leaveterm_localNameand all of the columns starting withlabeland onwards to the right. - Delete any rows whose terms are not being modified.
- Edit the cells whose values need to be changed.
- If a new term is being added, fill in a new row anywhere below the header row.
- Special care must be taken if columns are added (i.e. metadata properties are added). This is not for the faint of heart! The new columns must be added to every file used as source data for the various scripts and the column header mapping files also need to be edited. See [this page](for more details). This should be a rare event. DO NOT ever delete columns! If you want to elimite values for a property, just leave empty strings in all of the cells of that property's column.
- Create a new branch (or fork if you don't have push rights) of the rs.tdwg.org repo. Save your edited CSV file using some notable name in the process directory.
- Open the simplified_process_rs_tdwg_org.ipynb Jupyter notebook and follow these instructions to edit the configuration section of the script.
- Run the script, paying careful attention to whether particular sections are appropriate for what you are trying to accomplish. NOTE: there are still some kinks to be worked out for the borrowed terms (
dc:anddcterms:namespaces), but changes there should be rare. It is useful to monitor the diffs that are generated as sections of the script are run and make sure that the changes are reasonable. This is easily monitored if you are using the GitHub desktop client. - If there are changes to more than one namespace, repeat all of the previous steps with the second namespace before continuing on.
- When you are satisfied that all of the term, term list, vocabulary, and standards metadata changes are sensible, discard the changes made to the Jupyter notebook so that it will remain in it's "example" stage when the branch (or fork) is merged. Alternately, you can download the "example" notebook from GitHub to write over the version that you modified, and commit it to the branch.
- As of 2020-08-20, updating rs.tdwg.org document metadata must be done manually. Steve Baskauf knows how to do it and will try to eventually write a script to automate the process. It's best to ask him to do the updating before merging the branch.
- Push the branch to GitHub and create a pull request. It is best for someone to review the changes carefully before merging.
- Once the branch has been merged the data are available via HTTP to the other scripts that use those data.
- Create a branch of the Darwin Core repo.
- Edit the termlist-header.md file, changing "Date version issued", the "This version" URL, the version URL in the citation, and the date in the "1 Introduction" to the date used for the new version of Darwin Core. Change the "Previous version" date to the date of the version that is being replaced. Save the file.
- Go to the
docs/list/directory and change the name of theindex.mdfile to the date of the version being replaced (e.g.2020-08-12.md). Open that file and add a "Replaced by" label and value to the IRI of the new version (see an older version for an example). Save the file. - Run the script build-termlist.py. Be patient since some steps take a few seconds. When the
Donemessage appears, it's finished. - Check the diff for the newly generated
index.mdfile in the docs/list/ directory and make sure that the changes are appropriate. - Run the generate_term_versions.py script to generate a new version of term_versions.csv. This file serves as the source of data for the build script in the next step. At some point, that script may be modified to eliminate this intermediate step.
- Run the build.py script to build the Quick Reference Guide.
- Create a pull request for the new branch.
- When the branch has been reviewed carefully, merge the branch. The new pages shuld be live as soon as Jekyll rebuilds them on GitHub.
- Term dereferencing to human and machine readable representations is handled by a server managed by GBIF. Ask Matt Blissett to reload the data from the
rs.tdwg.orgrepo into the server (he has a script to do it.). Because dereferencing of current terms to human-readable web pages is handled by a redirect, there won't be any noticeable difference whether the data are reloaded in this step or not. But dereferencing the term versions, or dereferencing to acquire machine readable metadata will not reflect the new changes until the server is reloaded.
Build script
The build script build.py uses as input:
- vocabulary/term_versions.csv: the list of terms
- terms.tmpl: a Jinja2 template for the quick reference guide
And creates:
- The quick reference guide is a Markdown file at docs/terms/index.md. The guide is built as Markdown (with a lot of included html) rather than html, so it can be incorporated by Jekyll in the Darwin Core website (including a header, footer and table of contents).
- Two simple Darwin Core CSV files in dist/
Run the build script
-
Install the required libraries (once):
pip install -r requirements.txt -
Run the script from the command line:
python build.py
Generating the "normative document"
The script generate_normative_csv.py pulls source data from the rs.tdwg.org repository. The local file qrg-list.csv contains a list of the term IRIs in the order that they are to appear in the Quick Reference Guide. This list needs to be changed whenever terms are added to or deprecated from Darwin Core.
It generates the file term_versions.csv, which is used as the input for the build.py script above.
Generating the "list of terms" document
The Python script build-termlist.py inputs the header information from termlist-header.md, then builds the list of terms and their metadata from data in the rs.tdwg.org repository. The script also inputs termlist-footer.md and appends it to the end of the generated document, but currently it has no content. The constructed Markdown document is saved as /docs/list/index.md.
Last edited: 2020-08-20